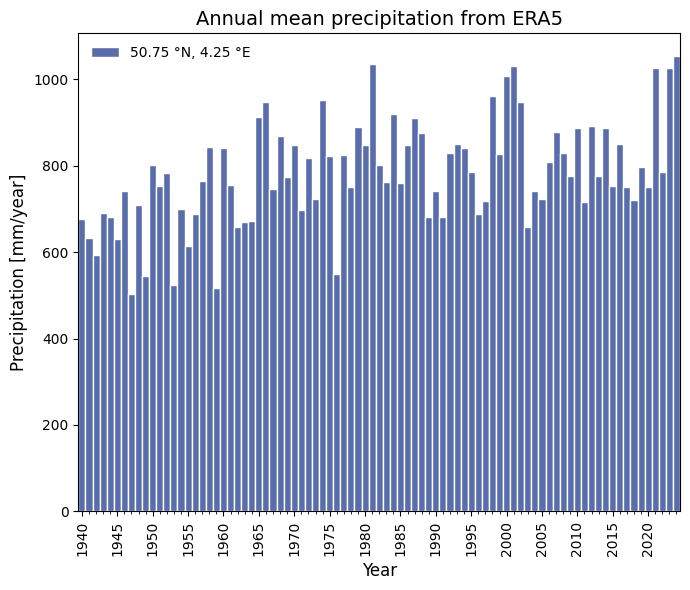
Calculate the annual precipitation timeseries from ERA5#
This notebook demonstrates how to retrieve, process, and plot the data displayed in the ERA Explorer
==> For further training materials, consider the Copernicus Climate Change Service (C3S) data tutorials
In this example we will be using earthkit to retrieve the data and standard Python packages to process and plot it.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
import earthkit.data
If you want to run this code yourself, make sure to get a CDS API key from the CDS website.
Following the guidance there, you’ll then need to set up your local .cdsapirc to be able to authenticate with the CDS and download data. Then, you will be able to customise the date ranges, variables, and much more!
This is the latitude/longitude that we will extract the nearest grid cell from. You can change these to plot different locations. You can see the currently used ones in the ERA Explorer URL. In this example we are plotting data at the gridpoint closest to Brussels, Belgium.
lat = 50.86
lng = 4.35
This is the variable we are getting from the ERA dataset, and the time period
variable = "total_precipitation"
date_range = ["1940-01-01", "2100-12-31"]
For convenience, we make a function to handle the data retrieval:
def retrieve_data(variable, date_range, lat, lng):
# Define the dataset and request parameters
dataset = "reanalysis-era5-single-levels-timeseries"
request = {
"variable": [
variable, # Variable to retrieve
],
"date": date_range, # Date range for the data
"location": {"longitude": lng, "latitude": lat}, # Location coordinates
"data_format": "netcdf" # Format of the retrieved data
}
# Use "earthkit" to retrieve the data
ekds = earthkit.data.from_source(
"cds", dataset, request
).to_xarray()
return ekds
Now let’s download the data!
data = retrieve_data(variable, date_range, lat, lng)
And let’s make some bespoke functions to process the data. Each one is described with a “””docstring”””
def truncate_data(var):
"""
Truncate the input dataset to include only complete years where the final hour
of December 31st is present in the dataset.
Args:
var (xarray.Dataset or xarray.DataArray): Input dataset containing a 'valid_time'
coordinate with datetime information.
Returns:
xarray.Dataset or xarray.DataArray: The truncated dataset containing data
only for complete years.
"""
# Create a range of the final hours of each year in the dataset
start_year = var.valid_time.dt.year.min().item()
end_year = var.valid_time.dt.year.max().item()
final_hours = pd.date_range(
f"{start_year}-12-31T23:00:00",
f"{end_year}-12-31T23:00:00",
freq="YE"
)
# Filter only the years where the final hour is in the dataset
valid_years = [
dt.year for dt in final_hours if dt in var.valid_time
]
# Select data for those years
var_truncated = var.sel(
valid_time=var.valid_time.dt.year.isin(valid_years)
)
return var_truncated
# Function to compute the annual mean precipitation time series
def precipAnnualTimeseries():
"""
Processes the annual timeseries of precipitation data.
This function reads precipitation data from a NetCDF file, removes data
for the incomplete current year, resamples the data to annual sums, and
converts the values to millimeters.
Returns:
tuple: A tuple containing two elements:
- years (numpy.ndarray): Years corresponding to the annual precip sums.
- values (numpy.ndarray): Annual precipitation sums in millimeters.
"""
data_tp_pt = data.tp
# Remove incomplete years
data_tp_pt_trun = truncate_data(data_tp_pt)
# Resample the data to annual sums and convert to mm
data_tp_pt_agg = data_tp_pt_trun.resample(
valid_time="YE"
).sum() * 1000
years = data_tp_pt_agg.valid_time.to_index().year
values = data_tp_pt_agg.values.flatten()
# Get the actual lat/lon used
nearest_lat = data_tp_pt.latitude.values
nearest_lng = data_tp_pt.longitude.values
return years, values, nearest_lat, nearest_lng
# Call the function and retrieve the data
years1, ts1, nearest_lat, nearest_lng = precipAnnualTimeseries()
And finally, let’s set up the plot nicely. This can easily be customised, but for now we do something similar to ERA Explorer
# Determine suffix for latitude (N/S) and longitude (E/W) based on their sign
latSuffix = 'N' if nearest_lat > 0 else 'S' # 'N' for +ve latitude, 'S' for -ve latitude
lngSuffix = 'E' if nearest_lng > 0 else 'W' # 'E' for +ve longitude, 'W' for -ve longitude
# Create a new figure with a specified size
plt.figure(figsize=(7, 6))
# Plot the data as a bar chart
plt.bar(
years1, # X-axis values (years)
ts1, # Y-axis values (precipitation values)
width=1, # Set the width of each bar to 1 unit
color='#596DAB', # Bar fill color
label=(
f'{abs(nearest_lat):.2f} °{latSuffix}, '
f'{abs(nearest_lng):.2f} °{lngSuffix}'
), # Location label for the legend
edgecolor='white', # Color of the edges of the bars
)
# Add a legend with a transparent background
plt.legend(framealpha=0)
# Customize x-axis ticks
plt.xticks(
np.arange(1940, 2100, 5), # X-ticks every 5 years
rotation=90 # Rotate tick labels vertically
)
# Set x-axis limits with a small buffer at the edges
plt.xlim(years1[0] - 0.5, years1[-1] + 0.5)
# Add minor ticks on the x-axis (every year)
plt.gca().xaxis.set_minor_locator(MultipleLocator(1)) # Minor ticks every 1 year
# Customize axis labels
plt.xlabel('Year', fontsize=12)
plt.ylabel('Precipitation [mm/year]', fontsize=12)
# Add a title to the plot
plt.title('Annual mean precipitation from ERA5', fontsize=14)
# Adjust layout to prevent overlapping labels
plt.tight_layout()
# Display the plot
plt.show()